
FreeNAS – Partea a 3-a: Tutorial ZFS, zpool și partiționare
![]() Tutorial avansat de partiționare, configurare ZFS și migrare de la două la trei discuri.
Tutorial avansat de partiționare, configurare ZFS și migrare de la două la trei discuri.
Ce putem face ca să păstrăm redundanța și toleranța la defectarea discurilor dar să folosim mai eficient spațiul de stocare?
Ce putem face împotriva fenomenului de “silent corruption” ?
RAID vs ZFS
Atât RAID-ul cât și ZFS-ul oferă mecanisme de redundanță. Totuși ZFS-ul are câteva avantaje:
- protecție la coruperea ascunsă a datelor “silent corruption” prin mecanisme de checksum pe fiecare bloc scris pe disc, un așa numit self-healing nativ
- deduplication – un mecanism de scriere o singură dată a unui fișier chiar dacă acesta se află de două sau mai multe ori pe disc, acest “feature” cere totuși resurse de RAM ECC și putere de procesare suplimentare dar și expune la risc în cazul unei căderi de tensiune neașteptate pentru că pot apărea coruperi ale datelor,
- posibilitatea de a face snapshot-uri ale setului de date la un moment dat,
- posibilitatea de a amesteca discuri de tipuri și capacități diferite în același set de date sau pool,
- în loc de fsck, scandisk, chkdsk etc folosite la alte sisteme de operare, ZFS oferă un tool, scrub, care permite detecția și corecția eventualelor erori apărute “on-the-fly” fără a fi nevoie ca pool-ul să fie offline, așa cum se întâmplă în cazul fsck sau chkdsk, totodată, scrub scanează datele în profunzime, nu doar câmpurile metadata, așa cum face fsck, procesul putând dura ore sau zile,
- fiind un sistem pe 128 de biți, permite scalare practic la infinit, teoretic fiind limitat la milioane de terabytes, permițând în felul acesta adăugarea oricâtor discuri la pool-ul de date,
- oferă compresie și criptare în mod nativ
- oferă mecanisme de accelerare în cazul folosirii de drive-uri SSD (ZIL, L2ARC)
- merge și fără plăci adaptoare de tip controller RAID, chiar sunt contraindicate, iar dacă sunt folosite, se recomandă trecerea lor în mod JBOD, în niciun caz RAID, pentru că vor interfera cu sistemele de detecție și corecție a erorilor ale ZFS,
- ZFS-ul este mult mai ieftin, fiind o soluție pur software.
Dezavantajele ZFS sunt memoria RAM necesară mai mare, de minim 2GB preferabil cu ECC, și puterea de calcul mai mare pentru acele checksum-uri nesfârșite. RAM-ul cu ECC este recomandat pentru a evita coruperea datelor în cazul funcționării cu o memorie defectă.
Cum folosim ZFS pe NAS-ul nostru?
Presupunem că pe NAS-ul nostru avem de stocat două feluri de date: multimedia, cu importanță moderată dar care ocupă mult și documente foarte importante care ocupă puțin dar pe care nu ne permitem să le pierdem. Vom arăta configurarea unui sistem cu trei discuri care oferă redundanță la pierderea unuia sau a două discuri.
Din cele trei discuri de 30GB pe care le avem la dispoziție pentru exemplificare, vom alege un spațiu util de 5GB pentru documente (pool-ul RAIDZ2) și vom lăsa restul pentru multimedia (pool-ul RAIDZ1).
În exemplul prezentat discurile sunt identificate cu daX din cauza mașinii virtuale, totuși, în cazul unui sistem real cu discuri SATA, acestea vor fi identificate cu adaX!
Pornind de la tutorialul precedent vom migra mirror-ul (cu două discuri) către un sistem cu trei discuri partiționate în două pool-uri RAIDZ1, respectiv RAIDZ2.
De exemplu, un pool cu trei discuri de 30GB în RAIDZ1 oferă redundanță la defectarea unui singur disc și o capacitate utilă de: 92% * 2 * 30GB = 55GB. Procentul de 92% poate scădea în cazul stocării a multor fișiere de mici dimensiuni. După același model, un pool RAIDZ2 din trei discuri de 30GB oferă redundanță la defectarea a două discuri, dar o capacitate de stocare de numai 92% *1 * 30 = 27GB.
Pentru pașii care urmează vom avea nevoie de command line shell. Găsiți aici cum se activează.
Migrarea unui pool ZFS de la MIRROR către două pool-uri RAIDZ1, respectiv RAIDZ2
Atenție! Procesul pe care îl vom parcurge împreună se poate să dureze mai multe ore, funcție de cantitatea de date aflată pe mirror-ul existent.
Ne asigurăm că cele două discuri sunt în stare bună, vizibile de către sistem: Storage -> View Disks
apoi că mirror-ul este funcțional: Storage -> Volumes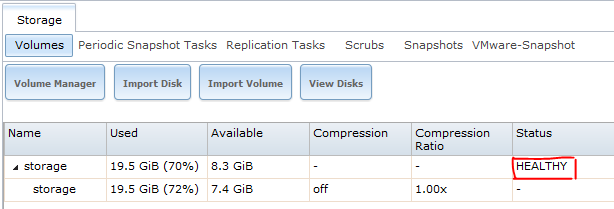
Oprim serverul NAS (cu ‘Shutdown’), montăm fizic cel de-al treilea disc și repornim NAS-ul. După repornire trebuie să vedem trei discuri prezente: Storage -> View Disks
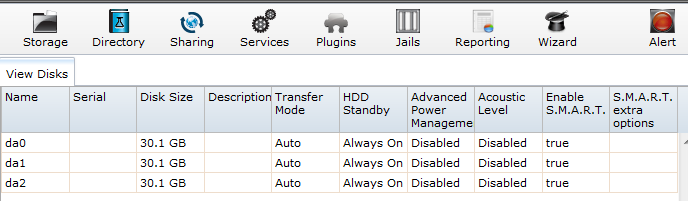
Dacă apare o eroare semnalizată prin clipirea semnului roșu alert, procedăm în continuare așa cum se vede în pasul 1, altfel, dacă nu sunt erori mergem direct la pasul 2.
1. Cum procedăm dacă după restart discurile nu mai sunt vizibile din cauza schimbării identificatorilor daX sau adaX?
Mergem la Storage și vedem că mirror-ul este degraded
Trebuie să identificăm eroarea, și anume discul dispărut și discul bun, încă vizibil în sistem.
Folosind shell-ul, verificăm care este problema pool-ului (-x ne va arăta doar pool-urile cu probleme):
# zpool status -x
În cazul nostru, observăm că discul da0 a dispărut:
pool: storage
state: DEGRADED
status: One or more devices could not be opened. Sufficient replicas exist for
the pool to continue functioning in a degraded state.
action: Attach the missing device and online it using 'zpool online'.
see: http://illumos.org/msg/ZFS-8000-2Q
scan: scrub repaired 0 in 0h18m with 0 errors on Sun Nov 22 17:22:50 2015
config:
NAME STATE READ WRITE CKSUM
storage DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
6177333059007759089 UNAVAIL 0 0 0 was /dev/da0p1
gptid/abace464-6882-11e5-baec-000c297a5a10 ONLINE 0 0 0
errors: No known data errors
Evident, mirror-ul este degraded, discul marcat de mine cu roșu este cel ascuns, iar cel cu verde este cel bun, care trebuie protejat cu orice preț, pentru că momentan acesta conține singura copie validă a datelor noastre!
În shell scriem:
# glabel status
și obținem ceva de forma
Name Status Components
gptid/abace464-6882-11e5-baec-000c297a5a10 N/A da1p1
gptid/31f215a9-67db-11e5-b967-000c297a5a10 N/A ada0p1
În lista de gptid-uri raportate de glabel, identificăm discul bun cu mare atenție, iar în cazul nostru observăm că acesta este da1. Prin urmare, acest da1 trebuie protejat în continuare. Prin eliminare, da2 este discul lipsă din mirror. Și pentru că ceea ce urmează să facem oricum ar fi implicat stergerea unuia dintre membrii mirror-ului, nu îi mai facem nimic lui da2. Dacă am fi avut nevoie să restaurăm mirror-ul am fi făcut un replace al discului unavailable cu acest da2.
Prin urmare avem:
- da0 – discul nou introdus, gol,
- da1 – discul cu date utile,
- da2 – discul care va fi golit
Acum sărim direct la pasul 3
2. Cum procedăm dacă după restart discurile sunt vizibile ca înainte și nu este semnalată nici o eroare?
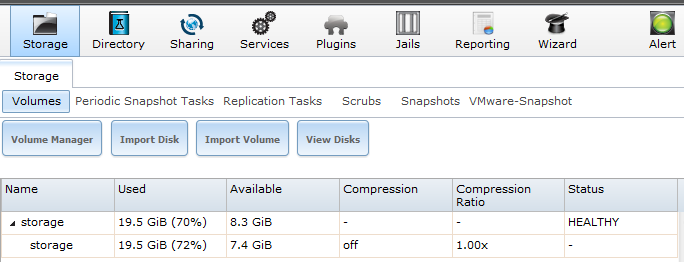
Pe scurt, pașii care urmează:
- rulăm scrub pentru a asigura integritatea mirror-ului
- identificăm membrii mirror-ului,
- stricăm mirror-ul, detașând unul dintre membri
Pe larg, cei trei pași sunt explicați în cele ce urmează.
- Rulăm scrub pentru a asigura integritatea mirror-ului
Procesul durează ceva timp depinzând de catitatea de date de pe discuri, deci asigurați-vă că poate rula chiar câteva ore:
# zpool scrub storage
după care urmărim evoluția procesului scrub executând din când în când comanda:
# zpool status storage
abia după ce scrub-ul termină de rulat putem trece la următorul pas
- Identificăm membrii mirror-ului
# zpool status storage
pool: storage state: ONLINE scan: scrub repaired 0 in 0h7m with 0 errors on Mon Nov 30 12:44:20 2015 config: NAME STATE READ WRITE CKSUM storage ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 gptid/abace464-6882-11e5-baec-000c297a5a10 ONLINE 0 0 0 gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 ONLINE 0 0 0 errors: No known data errors
după care identificăm gptid-urile:
# glabel status
Name Status Components gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 N/A da0p1 gptid/abace464-6882-11e5-baec-000c297a5a10 N/A da1p1 gptid/31f215a9-67db-11e5-b967-000c297a5a10 N/A ada0p1
- La următorul pas, stricăm mirror-ul prin eliminarea unuia dintre discuri
alegem să eliminăm da0 pentru a păstra compatibilitatea cu paragraful precedent
# zpool offline storage gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 # zpool status storage
pool: storage state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: scrub repaired 0 in 0h7m with 0 errors on Mon Nov 30 12:44:20 2015 config: NAME STATE READ WRITE CKSUM storage DEGRADED 0 0 0 mirror-0 DEGRADED 0 0 0 gptid/abace464-6882-11e5-baec-000c297a5a10 ONLINE 0 0 0 12985453911403560418 OFFLINE 0 0 0 was /dev/gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 errors: No known data error
verificăm din nou gptid-urile:
# glabel status
Name Status Components
gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 N/A da0p1
gptid/abace464-6882-11e5-baec-000c297a5a10 N/A da1p1
gptid/31f215a9-67db-11e5-b967-000c297a5a10 N/A ada0p1
Discul da1 este cel care trebuie protejat în continuare, acesta conținând singura copie a datelor noastre în acest moment!
3. Continuarea procesului indiferent dacă au fost sau nu erori după adăugarea celui de-al treilea disc
Pașii care urmează, pe scurt:
- partiționăm cele două discuri care nu aparțin mirror-ului
- creăm un disc virtual, în RAM, necesar la crearea pool-ului
- creăm primul pool, safe, de tip RAIDZ2 din cele două partiții mici și discul virtual
- eliminăm discul virtual din pool-ul safe
- creăm alt disc virtual din motive de conflict în zpool
- creăm al doilea pool, media, de tip RAIDZ1 din cele două partiții mari și discul virtual
- eliminăm discul virtual din pool-ul media
- ștergem discurile virtuale
- mutăm datele de pe discul rămas în mirror pe cele două pool-uri nou create
- distrugem mirror-ul
- partiționăm și cel de-al treilea disc
- înlocuim discul virtual din pool-ul safe cu partiția mică din cel de-al treilea disc
- înlocuim discul virtual din pool-ul media cu partiția mare din cel de-al treilea disc
- scrub pe pool-ul safe
- scrub pe pool-ul media
În cele ce urmează vom arăta pașii în detaliu.
- Partiționăm cele două discuri care nu aparțin mirror-ului
Verificăm starea partițiilor de pe cele trei discuri instalate:
# gpart show
=> 34 58720189 da1 GPT (28G) 34 94 - free - (47k) 128 58720088 1 freebsd-zfs (28G) 58720216 7 - free - (3.5k) => 34 15728573 ada0 GPT (7.5G) 34 1024 1 bios-boot (512k) 1058 6 - free - (3.0k) 1064 15727536 2 freebsd-zfs (7.5G) 15728600 7 - free - (3.5k) => 34 58720189 da0 GPT (28G) 34 58720189 1 freebsd-zfs (28G)
observăm că discul da2 nu este vizibil și asta deoarece nu este partiționat.
Ștergem eventualele partiții existente pe cele două discuri da0 și da2:
# gpart delete -i 1 da0 da0p1 deleted
# gpart destroy da0 da0 destroyed
Asemănător procedăm și cu da2, dacă este partiționat. Încă o dată, nu facem nicio operație asupra partițiilor discului da1!
Pentru schema noastră cu două niveluri de redundanță, vom crea următoarele partiții:
da0 - 5GB | 23GB da1 - 5GB | 23GB da2 - 5GB | 23GB
și următoarea organizare a celor două pool-uri:
safe - de tip raidz2 - da0p1 | da1p1 | da2p1 media - de tip raidz1 - da0p2 | da1p2 | da2p2
Acum începem crearea partițiilor:
# gpart create -s GPT da0 da0 created # gpart add -i 1 -a 4k -t freebsd-zfs -s 5G da0 da0p1 added # gpart add -i 2 -a 4k -t freebsd-zfs da0 da0p2 added # gpart create -s GPT da2 da2 created # gpart add -i 1 -a 4k -t freebsd-zfs -s 5G da2 da2p1 added # gpart add -i 2 -a 4k -t freebsd-zfs da2 da2p2 added
La final verificăm rezultatul:
# gpart show
=> 34 58720189 da1 GPT (28G) 34 94 - free - (47k) 128 58720088 1 freebsd-zfs (28G) 58720216 7 - free - (3.5k) => 34 15728573 ada0 GPT (7.5G) 34 1024 1 bios-boot (512k) 1058 6 - free - (3.0k) 1064 15727536 2 freebsd-zfs (7.5G) 15728600 7 - free - (3.5k) => 34 58720189 da0 GPT (28G) 34 6 - free - (3.0k) 40 10485760 1 freebsd-zfs (5.0G) 10485800 48234416 2 freebsd-zfs (23G) 58720216 7 - free - (3.5k) => 34 58720189 da2 GPT (28G) 34 6 - free - (3.0k) 40 10485760 1 freebsd-zfs (5.0G) 10485800 48234416 2 freebsd-zfs (23G) 58720216 7 - free - (3.5k)
Am marcat cu verde discurile proaspăt actualizate și cu roșu discul cu datele utile.
- Creăm un disc virtual, în RAM, necesar la crearea pool-ului
Discurile virtuale vor fi create în RAM și vor avea 6, respectiv 25GB, și chiar dacă nu avem atâta memorie nu vor fi probleme pentru că îl vom trece offline înainte de utilizarea efectivă a pool-ului. Dimensiunea aleasă pentru acest disc virtual trebuie să fie mai mare decât oricare dintre partițiile implicate în pool, altfel pool-ul creat nu va folosi la maximum partițiile. Discurile virtuale vor face parte din pool-uri, după care vor fi eliminate, iar pool-urile vor funcționa în degraded state, până la terminarea operațiunii de migrare.
Creăm discul virtual:
# mdconfig -a -t malloc -s 6G md0
- Creăm primul pool, safe, de tip RAIDZ2 din cele două partiții mici și discul virtual
# zpool create -f safe raidz2 /dev/da0p1 /dev/da2p1 /dev/md0
- Eliminăm discul virtual din pool-ul safe
# zpool offline safe /dev/md0
- Creăm alt disc virtual din motive de conflict în zpool
# mdconfig -a -t malloc -s 25G md1
- Creăm al doilea pool, media, de tip RAIDZ1 din cele două partiții mari și discul virtual
# zpool create -f media raidz1 /dev/da0p2 /dev/da2p2 /dev/md1
- Eliminăm discul virtual din pool-ul media
# zpool offline media /dev/md1
- Ștergem discurile virtuale
# mdconfig -d -u md0 # mdconfig -d -u md1
Verificăm pool-urile nou create:
# zpool status -x pool: media state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: none requested config: NAME STATE READ WRITE CKSUM media DEGRADED 0 0 0 raidz1-0 DEGRADED 0 0 0 da0p2 ONLINE 0 0 0 da2p2 ONLINE 0 0 0 11254977217173055466 OFFLINE 0 0 0 was /dev/md1 errors: No known data errors pool: safe state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: none requested config: NAME STATE READ WRITE CKSUM safe DEGRADED 0 0 0 raidz2-0 DEGRADED 0 0 0 da0p1 ONLINE 0 0 0 da2p1 ONLINE 0 0 0 12654067252789104954 OFFLINE 0 0 0 was /dev/md0 errors: No known data errors pool: storage state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: scrub repaired 0 in 0h7m with 0 errors on Mon Nov 30 12:44:20 2015 config: NAME STATE READ WRITE CKSUM storage DEGRADED 0 0 0 mirror-0 DEGRADED 0 0 0 gptid/abace464-6882-11e5-baec-000c297a5a10 ONLINE 0 0 0 12985453911403560418 OFFLINE 0 0 0 was /dev/gptid/f8f9726e-974a-11e5-a96b-000c297a5a10 errors: No known data errors
Și, evident, avem toate cele trei pool-uri degraded.
- Mutăm datele de pe discul rămas în mirror pe cele două pool-uri nou create
Mutarea datelor poate fi făcută fie automat printr-o comandă specială, fie manual prin copierea grupurilor de directoare și fișiere. Pentru că metodele manuale sunt la alegerea fiecăruia, vom insista doar asupra celor automate. Dintre acestea am ales pentru exemplificare două: zfs și rsync.
Prima metodă, zfs, este recomandată doar în cazul în care pool-ul țintă, în cazul nostru media, este gol. Dacă am urmat până acum întocmai pașii din tutorial, media este gol.
Mai întâi vom crea un snapshot al mirror-ului inițial, storage:
# zfs snapshot storage@now
apoi vom iniția un proces care va dura ceva timp, funcție de cantitatea de date aflată pe mirror. Recomand utilizarea unei console ssh, nu pe cea din webGUI:
# zfs send -R storage@now | zfs receive -F media
Consola va părea că s-a blocat. Nu are nicio problemă, comanda rulează mai mult timp fără să arate vreun semn vizibil, iar evoluția operației o putem urmări într-o consolă deschisă separat prin ssh:
# zfs list
Mai întâi am creat acel snapshot storage@now, pe care prin două comenzi concatenate zfs send și zfs receive conectate printr-un pipe, l-am trimis de pe pool-ul inițial storage către pool-ul destinație media. Flag-urile folosite -R se referă la recursivitate, iar -F forțează suprascrierea totală a pool-ului media, indiferent de ce s-ar afla pe el. De aceea acest pool destinație trebuie să fie gol. Vom observa că după rularea comenzilor zfs send/receive, încă un snapshot a fost creat media@now. După terminarea execuției zfs send/receive, cele două snapshot-uri pot fi listate și eventual șterse folosind comenzile de mai jos.
Câteva comenzi utile pentru zfs:
zfs list -t snapshot
– arată o listă a snapshot-urilor
zfs list -o space
– arată o listă cu spațiile ocupate
zfs destroy nume_pool@nume_snapshot
– șterge un snapshot
zfs snapshot nume_pool/nume_dataset@nume_snapshot
– creează un snapshot al unui set de date
Mai departe, copierea datelor în pool-ul safe se poate face fie manual cu cp, fie cum vom vedea mai jos, cu rsync.
După cum spuneam, cea de-a doua metodă de copiere propusă este rsync. Pentru a o folosi trebuie să avem montate cele două pool-uri proaspăt create. Bineînțeles acestea se pot monta și cu mount, dar noi vom folosi o metodă diferită. Mai întâi vom exporta cele două pool-uri:
# zpool export -f safe # zpool export -f media
După care le vom importa din webGUI:

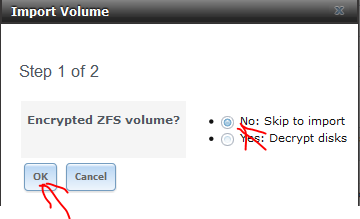

Importul durează până la câteva minute, după care repetăm operația și pentru pool-ul media, iar la final, toate cele trei pool-uri vor fi vizibile în webGUI:

Odată importate cele două pool-uri pot fi verificate cu mount, zpool status și pot fi sharate în rețea, la fel ca mirror-ul, așa cum am arătat în partea întâi a tutorialului.
Folosim rsync pentru copierea datelor din storage în media și safe:
# cd /mnt/storage # ls -al drwxrwxrwx 4 www www 5 Dec 1 20:34 ./ drwxr-xr-x 5 root wheel 160 Dec 1 20:25 ../ drwxrwxrwx 2 www www 5 Dec 1 20:28 Documents/ drwxrwxrwx 21 www www 21 Dec 1 15:17 Movies/ # rsync -ah Movies /mnt/media # rsync -ah Documents /mnt/safe
Observați lipsa caracterului ‘/’ de la finalul numelor Movies și Documents. Lipsa acelui caracter determină rsync să copieze cu tot cu directoarele părinte, Movies, respectiv Documents.
Pentru a fi accesibile din rețea, vom asigura un share prin CIFS, așa cum am văzut la finalul părții întâi a tutorialului. După ce ne asigurăm că fișierele sunt accesibile și toate la locul lor, putem trece la ștergerea mirror-ului și aducerea pool-urilor media și safe din degraded în healthy. Totodată ar trebui scos share-ul CIFS de pe calea /mnt/storage și rulate din nou comenzile chmod si chown, așa cum am văzut în prima parte.
Mai întâi ștergem mirror-ul:
# zpool destroy storage
apoi scoatem pool-ul storage și din webGUI:


apoi repartiționăm discul recuperat din mirror:
# gpart show
=> 34 58720189 da0 GPT (28G)
34 6 - free - (3.0k)
40 10485760 1 freebsd-zfs (5.0G)
10485800 48234416 2 freebsd-zfs (23G)
58720216 7 - free - (3.5k)
=> 34 58720189 da1 GPT (28G)
34 58720189 1 freebsd-zfs (28G)
=> 34 58720189 da2 GPT (28G)
34 6 - free - (3.0k)
40 10485760 1 freebsd-zfs (5.0G)
10485800 48234416 2 freebsd-zfs (23G)
58720216 7 - free - (3.5k)
=> 34 15728573 ada0 GPT (7.5G)
34 1024 1 bios-boot (512k)
1058 6 - free - (3.0k)
1064 15727536 2 freebsd-zfs (7.5G)
15728600 7 - free - (3.5k)
# gpart delete -i 1 da1
da1p1 deleted
# gpart destroy da1
da1 destroyed
# gpart create -s GPT da1
da1 created
# gpart add -i 1 -a 4k -t freebsd-zfs -s 5G da1
da1p1 added
# gpart add -i 2 -a 4k -t freebsd-zfs da1
da1p2 added
Procesul ce urmează, resilvering, durează ceva timp pentru fiecare dintre pool-uri.
Înlocuim partiția lipsă din safe:
# zpool status safe pool: safe state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: scrub repaired 0 in 0h0m with 0 errors on Tue Dec 1 18:14:01 2015 config: NAME STATE READ WRITE CKSUM safe DEGRADED 0 0 0 raidz2-0 DEGRADED 0 0 0 da0p1 ONLINE 0 0 0 da2p1 ONLINE 0 0 0 130833272578055237 OFFLINE 0 0 0 was /dev/md0 errors: No known data errors # zpool replace safe 130833272578055237 /dev/da1p1
procesul de replace poate dura câteva ore sau zile așa că ne înarmăm cu răbdare, timp în care putem urmări evoluția cu zpool status safe. Nu este recomandat să facem două operații de replace simultan pe mai multe pool-uri din motive de performanță, stres al componentelor și de siguranța datelor.
După ce s-a încheiat operația precedentă, continuăm cu următorul pool:
# zpool status media pool: media state: DEGRADED status: One or more devices has been taken offline by the administrator. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Online the device using 'zpool online' or replace the device with 'zpool replace'. scan: scrub repaired 0 in 0h9m with 0 errors on Tue Dec 1 18:23:25 2015 config: NAME STATE READ WRITE CKSUM media DEGRADED 0 0 0 raidz1-0 DEGRADED 0 0 0 da0p2 ONLINE 0 0 0 da2p2 ONLINE 0 0 0 13465919965475166454 OFFLINE 0 0 0 was /dev/md1 errors: No known data errors # zpool replace media 13465919965475166454 /dev/da1p2
În timpul procesului de resilvering, cam așa arată rezultatul comenzii zpool status:
pool: media state: DEGRADED status: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state. action: Wait for the resilver to complete. scan: resilver in progress since Tue Dec 1 21:51:18 2015 21.5G scanned out of 28.3G at 22.9M/s, 0h5m to go 7.17G resilvered, 76.11% done config: NAME STATE READ WRITE CKSUM media DEGRADED 0 0 0 raidz1-0 DEGRADED 0 0 0 da0p2 ONLINE 0 0 0 da2p2 ONLINE 0 0 0 replacing-2 OFFLINE 0 0 0 13465919965475166454 OFFLINE 0 0 0 was /dev/md1 da1p2 ONLINE 0 0 0 (resilvering) errors: No known data errors
După încheierea înlocuirilor, în webGUI ar trebui să fie totul healthy
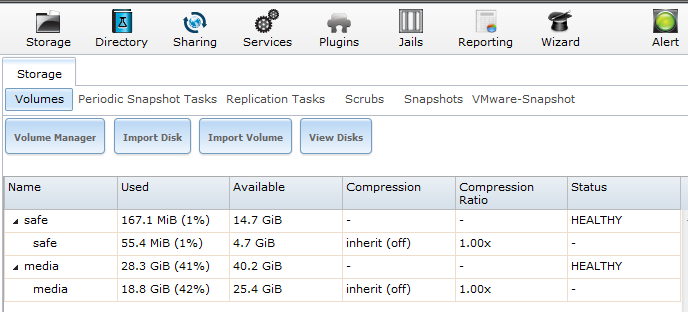
La final, dacă doriți și vă permite timpul, puteți să mai rulați câte un scrub, pe rând, pe fiecare dintre pool-uri.
EnjoY 🙂
Urmează:
- FreeNAS – Partea a 4-a: norişorul din NAS

No Responses